Hello,
Can you please share a screenshot of the report you see from your end? Please click on the affected sitemap to reveal the complete details of the error.
Looking forward to hearing back from you.
Error message: It says html site map, but I keep getting errors.
Hello,
Google hasn’t read the page sitemap after the submission, and that’s why it is still showing the error. Please wait for Google to crawl the page sitemap again and the issue should be resolved after that.
Please do not hesitate to let us know if you need our assistance with anything else.
Thank you.
my sitemap = ?sitemap=1
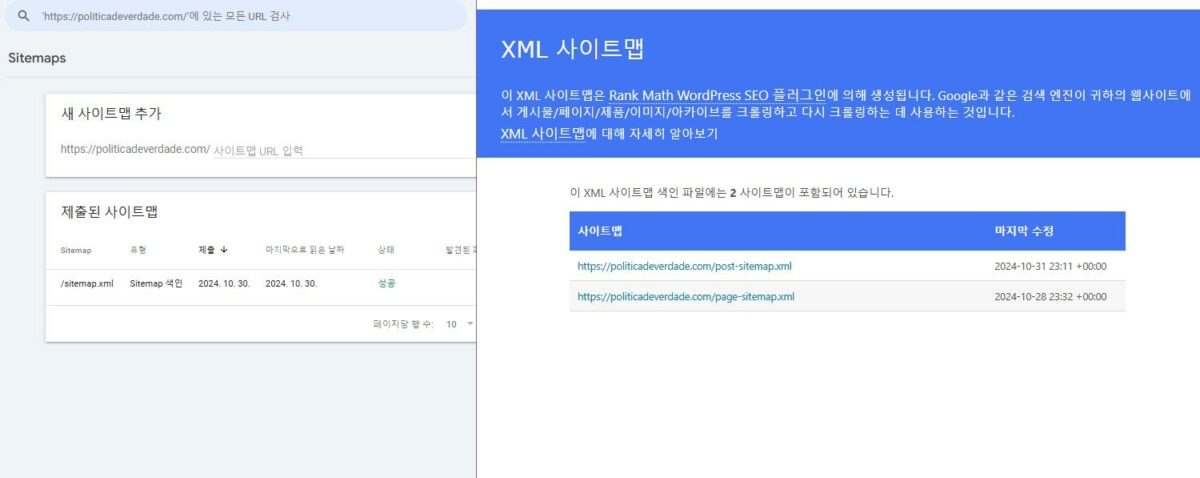
I registered under the title of the site map you told me. As you can see, there are several registered, is there any problem with exposing several?
Hello,
You do not need to have several sitemaps submitted, just one of them is sufficient.
Ideally, you should have only the main sitemap with URL /sitemap_index.xml.
We suggested the /?sitemap=1 ‘version’ to encourage Googlebot to crawl it sooner.
Please remove all the sitemaps and submit only /?sitemap=1.
We hope that helps.
Thank you.
* Indexing pages – Crawled – no current index generated
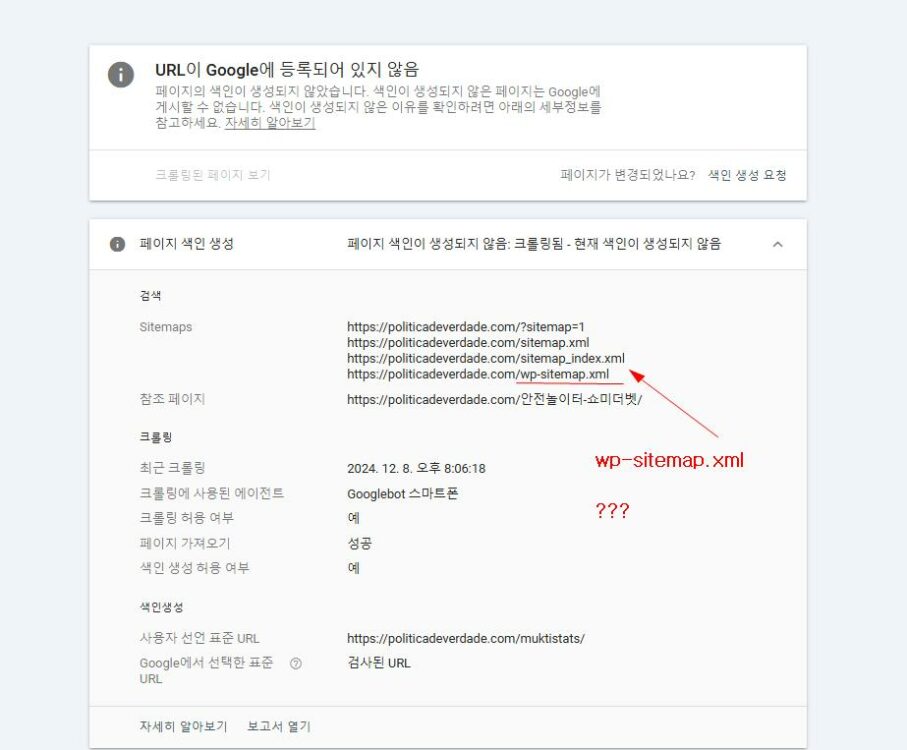
If you look at the screenshot, it’s all attached file images that are registered in the post. Do you know why these things are getting errors?
Hello,
It is normal for .webp images to appear under “Crawled – Currently Not Indexed” because Google indexes images differently from web pages.
Google can sometimes crawl images (especially .webp), JavaScript, or RSS feeds and determine that they are not considered a “page” after it has accessed the URL. In such cases, these URLs are listed under “Crawled – Currently Not Indexed.” This is not a cause for concern and does not mean that your images will not be crawled or indexed by the Google Image crawler. The page indexing and URL inspection report reflects the crawl activities and decisions made by the Googlebot page crawler, not the Googlebot-Image crawler. Learn more here.
If you prefer not to see .webp URLs listed as “Crawled – Currently Not Indexed,” you can add a disallow rule for the Google page crawler to prevent it from crawling .webp URLs. Here’s an example of a robots.txt rule you can use:
User-agent: Googlebot
Disallow: /*.webp$
User-agent: Googlebot-Image
Allow: /*.webp$
We hope this clarifies the issue. Please let us know if you have any further questions or concerns.

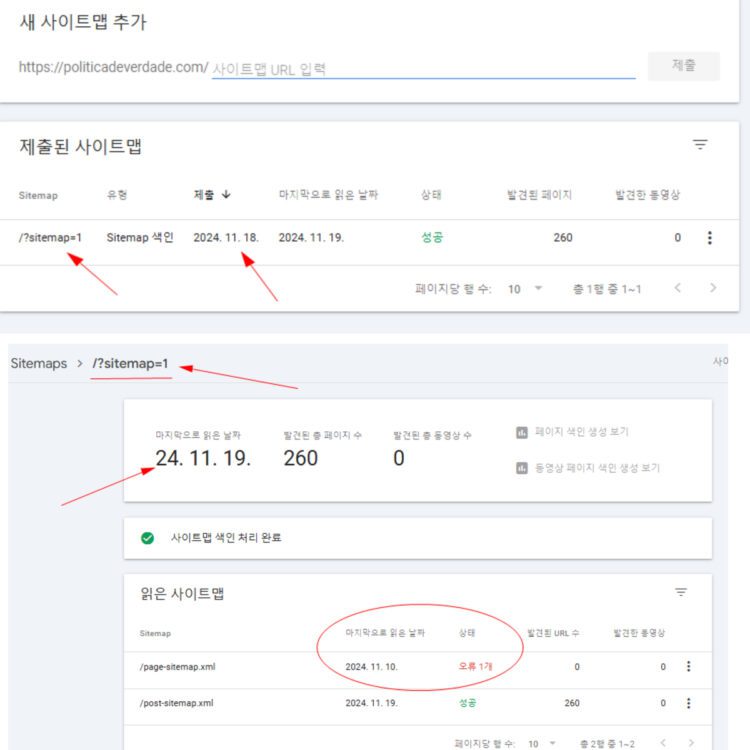
I put in the first site map that you recommend.
But the problem of still getting three, the resulting error is constantly happening. What should I do?
Hello,
If Google has discovered a URL from a previous sitemap, it will still be listed in the inspection result, even if you have removed it from GSC’s sitemap section. Google remembers all the sitemaps it used to discover the URL, even if they no longer exist. This is the normal behavior of GSC and is not an issue.
Hope that helps and please do not hesitate to let us know if you need our assistance with anything else.

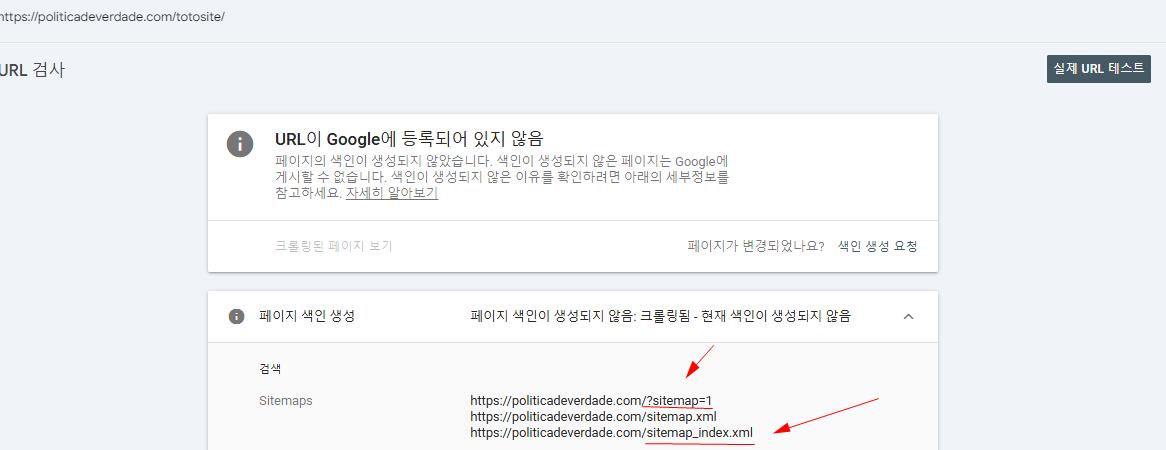
It wasn’t there until yesterday. I see a new site map in the error message today. What is this? How can I remove it?
Hello,
It’s important to note that the data on Google Search Console is preserved for historical reference and the sitemap you are seeing there it’s an old sitemap that was available on your website before and where the page you searched for was also seen by Google.
Don’t hesitate to get in touch if you have any other questions.
/?sitemap=1
I think there are a lot of errors when I put in the site map you taught me, is it correct to keep submitting that site map?
I’ve been observing the index capability, and since I changed it to the name of that site map, it’s been continuously falling
Hello,
Since we did not hear back from you for 15 days, we are assuming that you found the solution. We are closing this support ticket.
If you still need assistance or any other help, please feel free to open a new support ticket, and we will be more than happy to assist.
Thank you.