Hello, we’re sorry to hear that you’re experiencing issues with Search Console detecting pages with /feed/. This issue can occur when the feed URL is being indexed by Google, and it’s not declared as canonical by the user.
To solve this problem, you can follow these steps:
-
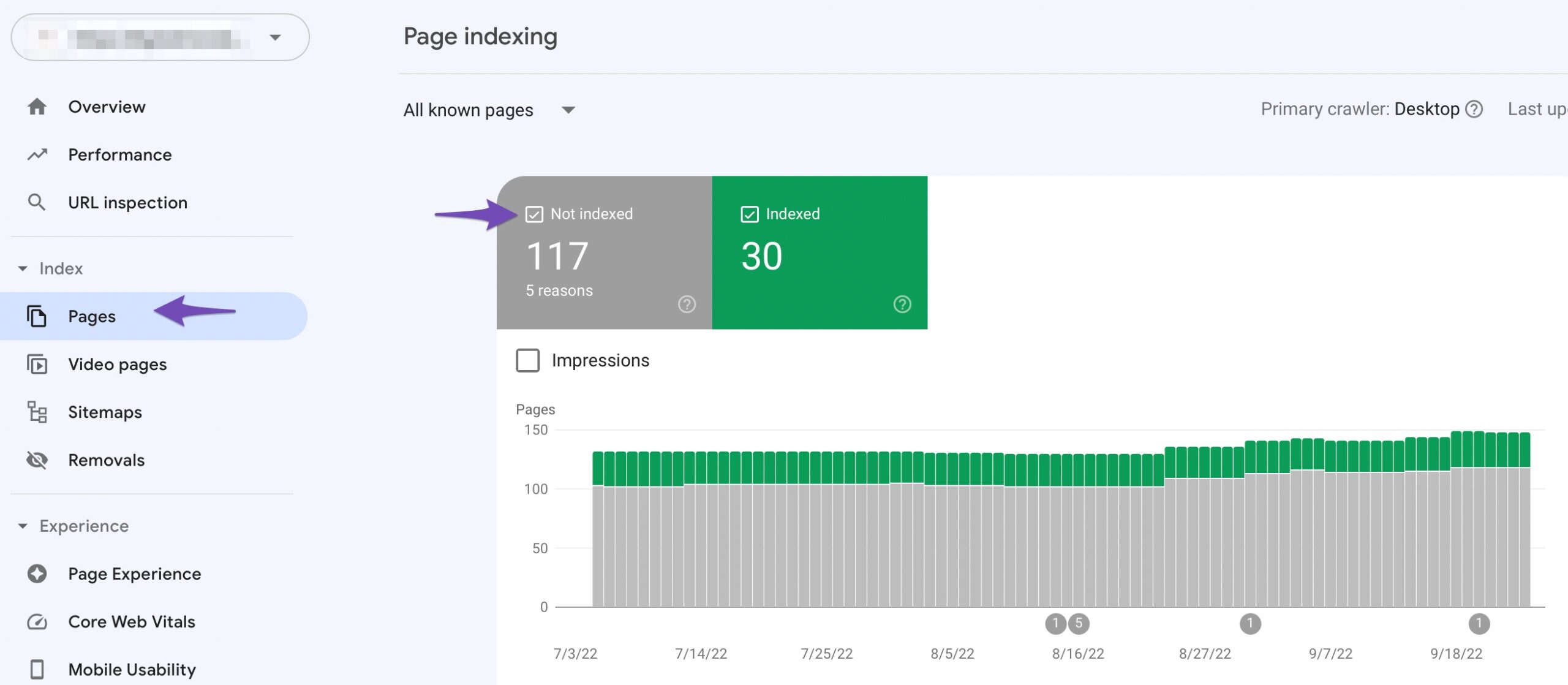
Use Google Search Console to Identify Pages:
- Go to the Pages section of Google Search Console and click on the Not indexed tab.
- Then, click on the “Duplicate, Google chose different canonical than user” status.
- This will show you a list of all the pages on your website that are affected by this issue.
-
Use Rank Math’s Analytics to Identify Pages With the Problem:
- Navigate to Rank Math > Analytics in the WordPress dashboard and click on the Index Status tab.
- You can filter the posts’ index status using the drop-down menu to identify the pages with the problem.
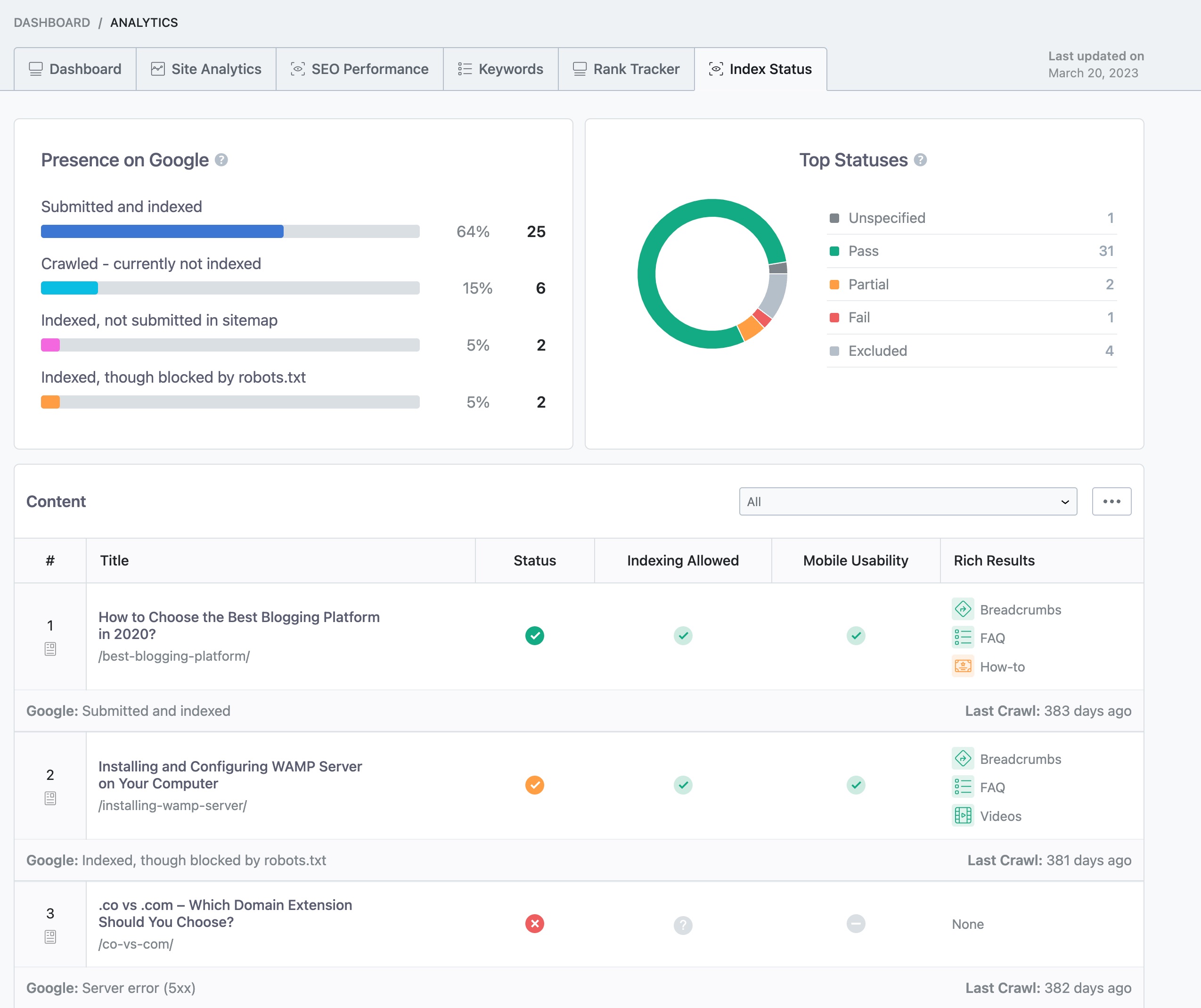
Once you’ve identified the pages with the problem, you can proceed to fix them.
If you have any further questions or need additional assistance, please feel free to reach out to our dedicated support team here. We’re available 24/7, 365 days a year and we’d be happy to help.
Sources:
How to Fix “Duplicate, Google Chose Different Canonical than User” » Rank Math
How to Fix ‘Duplicate, Submitted URL Not Selected as Canonical’ Issue in Google Search Console » Rank Math
How to Fix ‘Blocked by robots.txt’ Error in Google Search Console » Rank Math
Why GSC Shows “No Referring Sitemaps Detected”
How to Show Images in the Search Results » Rank Math
Hello,
Feed URLs are not created for humans but for RSS feed crawlers and readers. They are only basic code versions of your actual content pages.
If you have feed pages, ensure that they are not set to index. You do not want these pages to be indexed as Google doesn’t like them and would most likely not show them to users anyway.
Also, if you want to disable them on your site, you can follow this guide:
https://kinsta.com/knowledgebase/wordpress-disable-rss-feed/
Alternatively, you can disallow bots from crawling the feed URLs from the robots.txt file at WordPress Dashboard > Rank Math > General Settings > Edit Robots.txt
User-Agent: *
Disallow: */feed/
Hope that helps.
Before proceeding with the modification to the robots, I would like to know why you didn’t put this rule automatically?
Will search engines automatically exclude all previously discovered /feed/ addresses if I add the robots.txt rule?
Hello,
The reason Rank Math doesn’t automatically include the rule to disallow crawling of the /feed/ URLs in the robots.txt file is that some websites might have specific use cases where they want certain feed URLs to be indexed.
Adding the rule in robots.txt is a manual step because it provides website owners with flexibility and control over what content they want search engines to crawl and index. By default, search engines respect the rules defined in the robots.txt file, and adding the rule there ensures that they won’t crawl the /feed/ URLs.
When you add the rule to disallow crawling of /feed/ URLs in robots.txt, search engines will follow this rule, and over time, the previously discovered /feed/ addresses will be excluded from indexing. It might take some time for search engines to process these changes and update their index.
We hope this helps. Please let us know if you have further questions or concerns.
Thank you.